Beyond Basic Caching
7 Jan, 2026Target audience:
Developers who shipped a cache and now have more problems than before.
Caching does more than reduce latency
Many developers treat caching as a latency optimization. Lowering P95 helps, but caching also gives us fault tolerance: we can keep serving requests when an upstream slows down or fails.
In a high-traffic service at Coolblue that I was optimizing, I implemented new caching strategies. Some data fetching moved out of the request scope into background jobs, but not all data stayed constant. Some data was unique per request and had to be fetched during the request.
I’ll walk you through my approach, step by step, using a hypothetical scenario.
0. No caching
Let’s set a baseline. In this hypothetical service, we read from an upstream (database, API, pigeon, etc.) and return the result.
Our latency matches upstream latency, plus a few milliseconds for request processing. If the upstream is slow, our service is slow. If the upstream is down, our service is down. It’s a simple implementation, but not a very robust one.
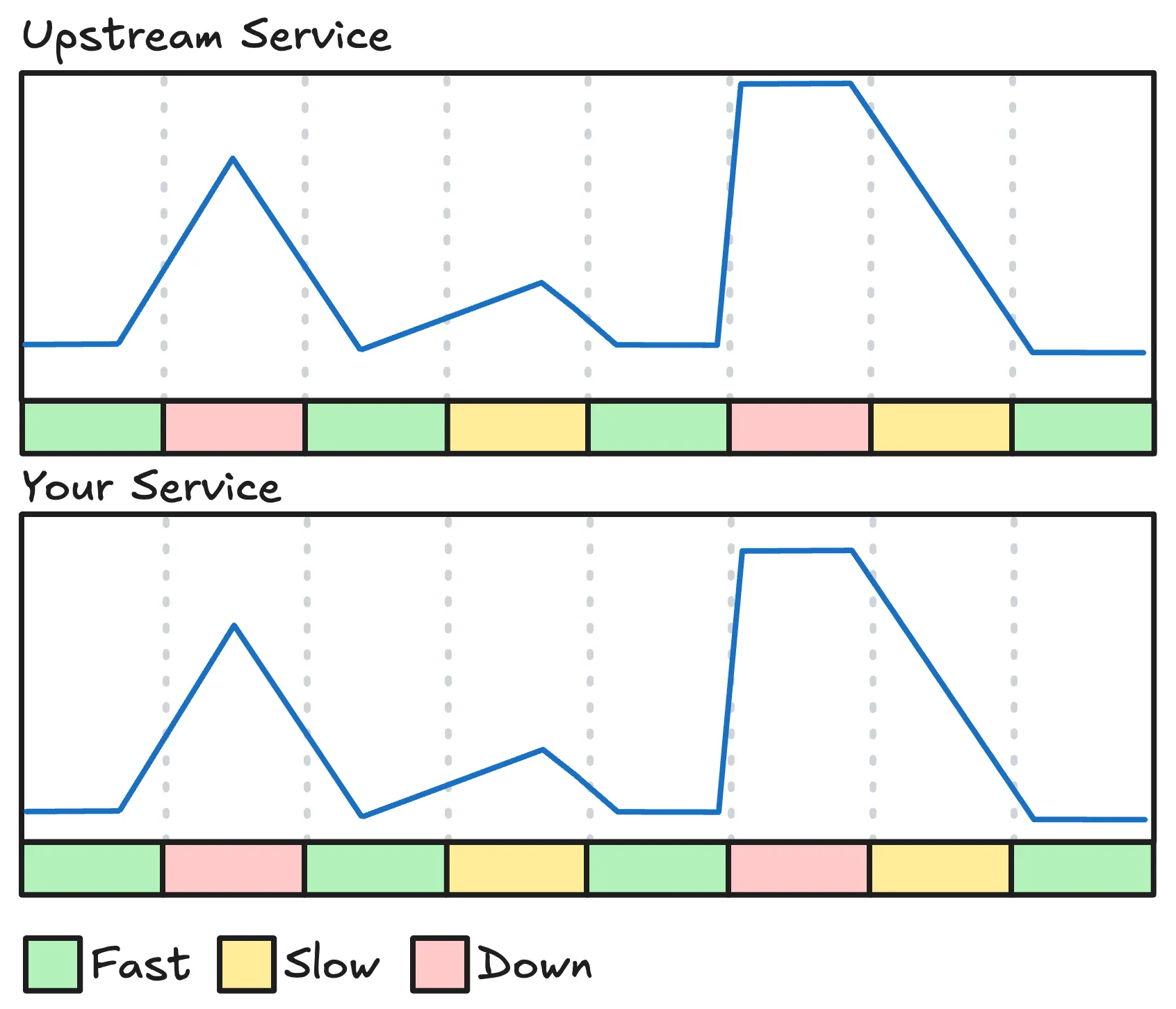
1. Normal caching
At some point, someone adds a cache to speed things up. With a cache between our service and the upstream service, we can reduce how often we call the upstream.
Most requests become fast, but when a key expires we pay the full upstream latency cost again. If the upstream slows down, those refreshes slow down too. If the upstream goes down, the cache never refills and our service goes down with the upstream again.
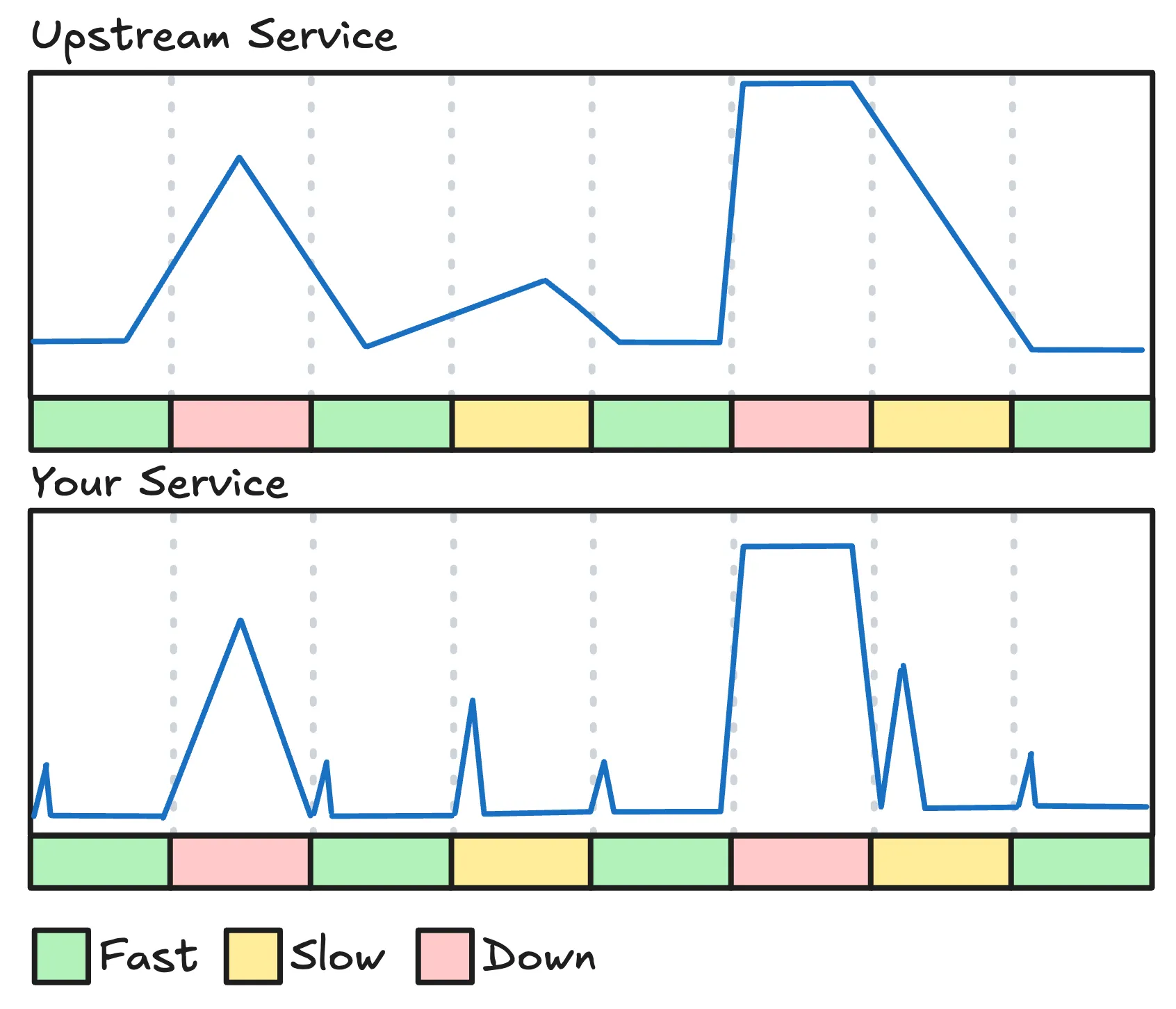
On a good day, this gives us a spiky P99 where some requests eat the cost of fetching fresh data. On a bad day, these cache misses turn into outages.
2. Stale-While-Revalidate
A binary cache state (hit or miss) is not good enough for a high-availability system. It forces us to fetch fresh data during the request whenever the cache expires.
In most systems, if the upstream times out or fails, serving stale data beats returning a 500 or timing out the request.
Instead, we can treat cache entries as three states:
- Fresh: Data that is still recent enough to use.
- Stale: Old data we keep around while we refresh it in the background.
- Missing: No data.
This splits a “hit” into fresh and stale. When freshness expires, we can still serve the last known value and start a refresh in the background. When a background refresh fails, we can keep serving the stale value and retry with backoff. This prevents one upstream incident from turning into a cascade of timeouts.
This way requests stay fast and the system keeps working during upstream outages.
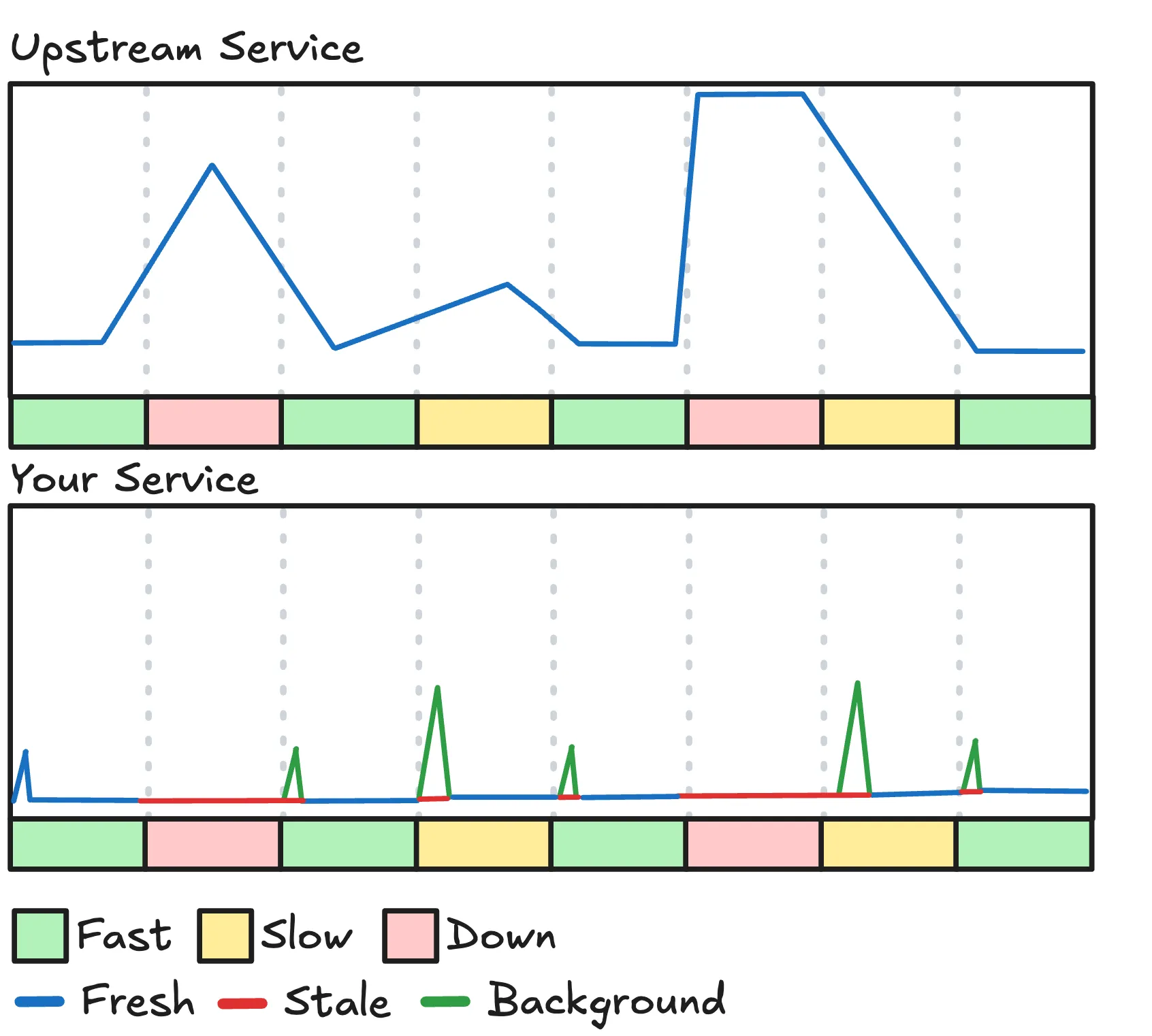
3. Cache Stampede Protection
When a hot key expires under load (say 1,000 requests per second), many requests miss at once and hammer the upstream. This is a cache stampede (or thundering herd).
This hurts the upstream because caching made it expect lower load. A stampede can push it over its limits, which creates more timeouts and more retries, which creates more load. This can be a downward spiral of systems going down, coming back up, and going down again.
We can prevent this with request coalescing. When we trigger a refresh, mark the key as “in-flight”. Subsequent requests for that key do not start new fetches. They either return the stale value (if we allow staleness), or wait for the in-flight refresh to complete.
In a single-instance setup, an in-memory map of in-flight promises can work. In a multi-instance setup, we may need a distributed lock if every instance can stampede at once. However, most of the time it’s OK to do N requests where N is our instance count, just not N * M where M is our requests per second per instance.
Another low-effort mitigation is to add TTL jitter. This means offsetting our keys by a few seconds/minutes when we SET them, so our hot keys don’t expire at the same time across instances.
4. Cold Starts
If we use in-memory caching without a shared cache and we cache a lot of data, new instances pay a large latency cost while they warm their empty caches.
To reduce cold-start pain (especially in serverless environments), we can add a distributed cache like Redis. A distributed cache stays warm across instances and survives instance restarts.
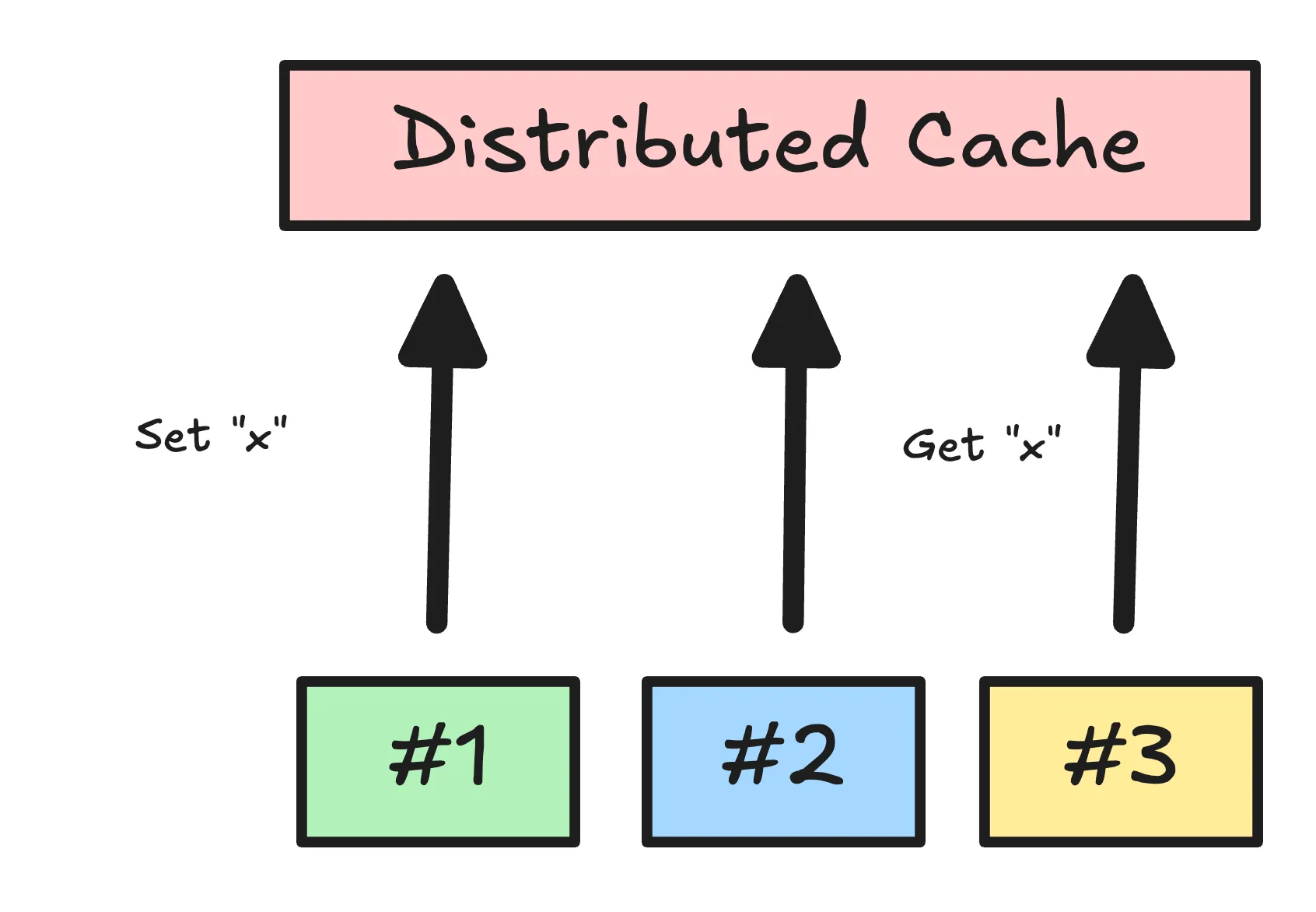
However, a distributed cache is not free. It’s a separate system that adds latency and brings its own failure modes. A common compromise is a hybrid cache: an in-memory cache per instance plus a shared distributed cache.
We pay double writes (memory + distributed), but we can buffer reads:
- Check memory
- Then check Redis
- Then fetch from the upstream (or refresh in the background if we have stale data)
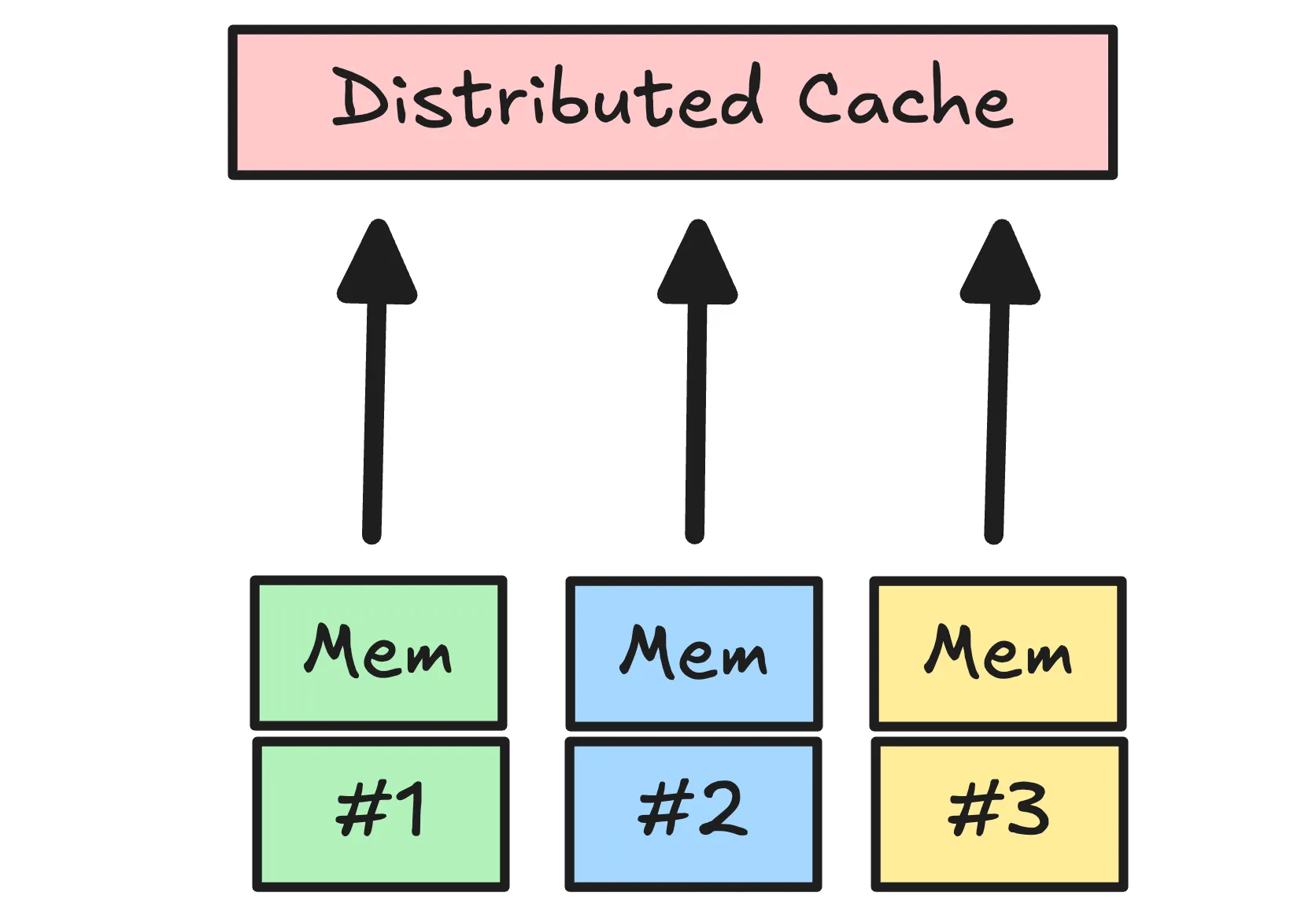
This setup reduces our P99 latency and gives us options when Redis or the upstream misbehaves.
5. Backplane
With multiple caches across instances, we face a new problem: updates. If we update a single instance, we can serve inconsistent data between instances.
If keys have short TTLs or the data changes little, this might not matter. In the service I optimized, instance A thinking a product weighed 1.01kg while instance B assumed 1.02kg did not break anything. Eventual consistency was OK for that system.
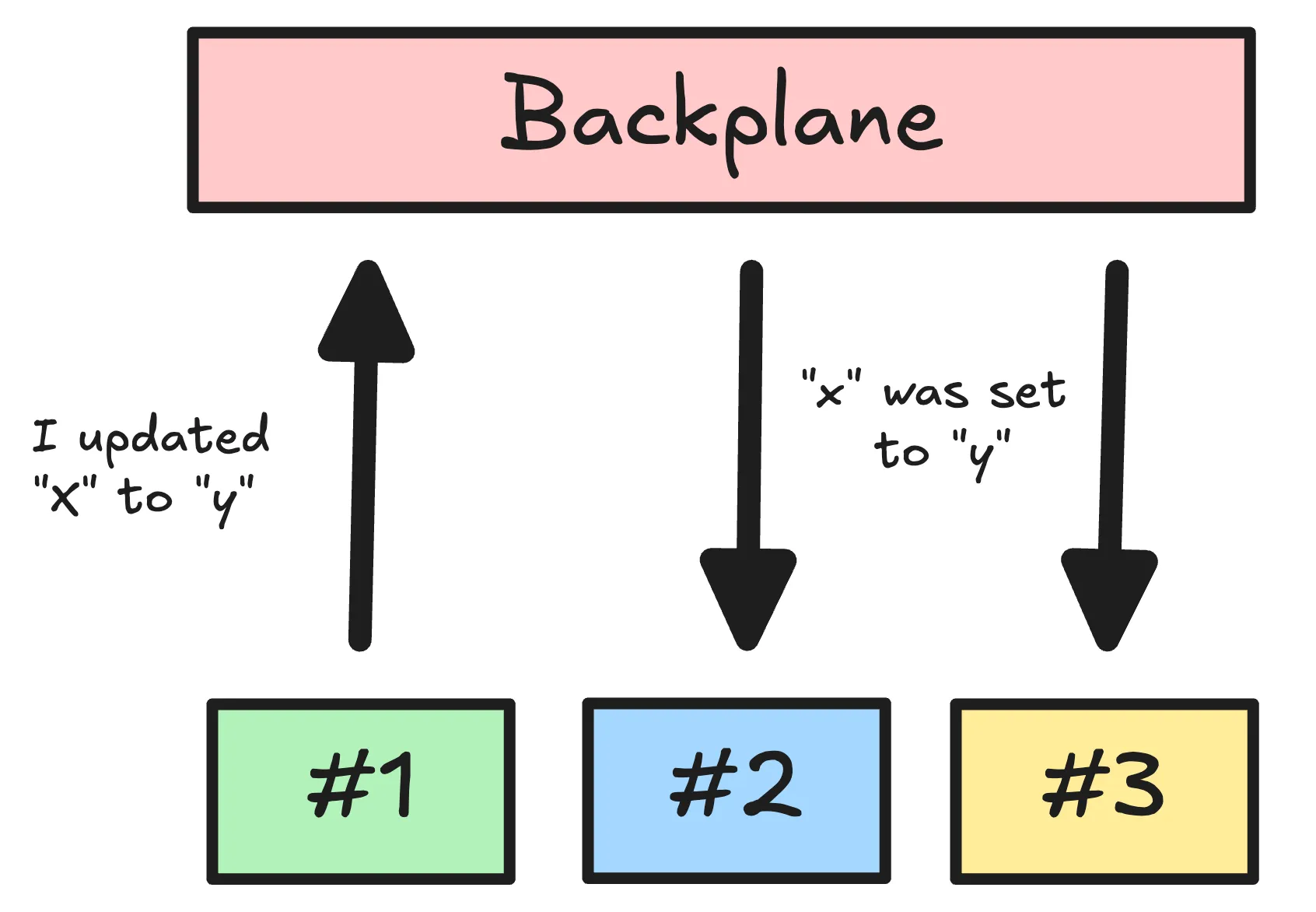
If we want to reduce those windows of inconsistency, we can add a backplane.
A backplane lets instances broadcast cache updates or invalidations. When one instance writes to its cache, it publishes an event so other instances can update their in-memory caches instead of waiting for TTL expiry.
We can implement this with Redis Pub/Sub if we already run Redis for caching. Each instance subscribes to a channel and publishes cache writes (or invalidations) to it. On receiving the event, instances update or evict their memory cache entry.
Conclusion
This step-by-step approach mirrors how I improved the caching implementation in my own systems.
I took inspiration from FusionCache, which implements many of these ideas for .NET.
I wanted the same building blocks in TypeScript, so I built it myself.
The TypeScript POC for this can be found in the tiered-cache repo on my GitHub. The final implementation is closed-source for now.